
FIGS (Quick Interpretable Greedy-tree Amounts): An approach for constructing interpretable designs by at the same time growing an ensemble of choice trees in competitors with one another.
Current machine-learning advances have actually caused significantly complicated predictive designs, frequently at the expense of interpretability. We frequently require interpretability, especially in high-stakes applications such as in scientific decision-making; interpretable designs assist with all examples, such as determining mistakes, leveraging domain understanding, and making fast forecasts.
In this post we’ll cover FIGS, a brand-new approach for fitting an interpretable design that takes the kind of an amount of trees. Real-world experiments and theoretical outcomes reveal that FIGS can successfully adjust to a wide variety of structure in information, accomplishing modern efficiency in numerous settings, all without compromising interpretability.
How does FIGS work?
Intuitively, FIGS works by extending CART, a normal greedy algorithm for growing a choice tree, to think about growing a amount of trees at the same time (see Fig 1). At each version, FIGS might grow any existing tree it has actually currently begun or begin a brand-new tree; it greedily picks whichever guideline decreases the overall unusual variation (or an alternative splitting requirement) one of the most. To keep the trees in sync with one another, each tree is made to anticipate the residuals staying after summing the forecasts of all other trees (see the paper for more information).
FIGS is intuitively comparable to ensemble techniques such as gradient improving/ random forest, however significantly because all trees are grown to take on each other the design can adjust more to the underlying structure in the information. The variety of trees and size/shape of each tree emerge instantly from the information instead of being by hand defined.

Fig 1. Top-level instinct for how FIGS fits a design.
An example utilizing FIGS
Utilizing FIGS is exceptionally basic. It is quickly installable through the imodels plan ( pip set up imodels) and after that can be utilized in the very same method as basic scikit-learn designs: merely import a classifier or regressor and utilize the fit and anticipate techniques. Here’s a complete example of utilizing it on a sample scientific dataset in which the target is threat of cervical spinal column injury (CSI).
from imodels import FIGSClassifier, get_clean_dataset
from sklearn.model _ choice import train_test_split
# prepare information (in this a sample scientific dataset).
X, y, feat_names = get_clean_dataset(' csi_pecarn_pred')
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.33, random_state = 42)
# fit the design.
design = FIGSClassifier( max_rules = 4) # initialize a design.
design fit( X_train, y_train) # fit design.
preds = design anticipate( X_test) # discrete forecasts: shape is (n_test, 1).
preds_proba = design predict_proba( X_test) # forecasted possibilities: shape is (n_test, n_classes).
# envision the design.
design plot( feature_names = feat_names, filename =' out.svg', dpi = 300)
This leads to an easy design– it consists of just 4 divides (because we defined that the design ought to run out than 4 divides ( max_rules= 4). Forecasts are made by dropping a sample down every tree, and summing the threat modification worths gotten from the resulting leaves of each tree. This design is exceptionally interpretable, as a doctor can now (i) quickly make forecasts utilizing the 4 pertinent functions and (ii) veterinarian the design to guarantee it matches their domain know-how. Keep in mind that this design is simply for illustration functions, and attains ~ 84% precision.

Fig 2. Basic design found out by FIGS for anticipating threat of cervical spine injury.
If we desire a more versatile design, we can likewise eliminate the restriction on the variety of guidelines (altering the code to design = FIGSClassifier()), leading to a bigger design (see Fig 3). Keep in mind that the variety of trees and how well balanced they are emerges from the structure of the information– just the overall variety of guidelines might be defined.

Fig 3. A little bigger design found out by FIGS for anticipating threat of cervical spine injury.
How well does FIGS carry out?
In a lot of cases when interpretability is wanted, such as clinical-decision-rule modeling, FIGS has the ability to attain modern efficiency. For instance, Fig 4 reveals various datasets where FIGS attains exceptional efficiency, especially when restricted to utilizing really couple of overall divides.
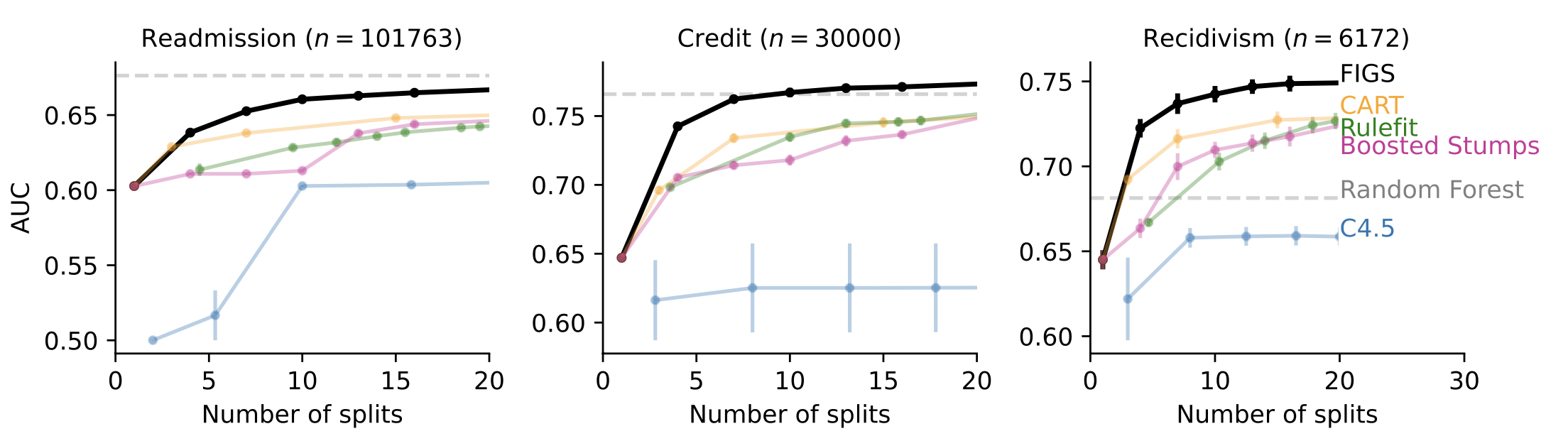
Fig 4. FIGS anticipates well with really couple of divides.
Why does FIGS carry out well?
FIGS is inspired by the observation that single choice trees frequently have divides that are duplicated in various branches, which might happen when there is additive structure in the information. Having several trees assists to prevent this by disentangling the additive elements into different trees.
Conclusion
General, interpretable modeling provides an alternative to typical black-box modeling, and in a lot of cases can provide huge enhancements in regards to effectiveness and openness without struggling with a loss in efficiency.
This post is based upon 2 documents: FIGS and G-FIGS— all code is readily available through the imodels plan This is joint deal with Keyan Nasseri, Abhineet Agarwal, James Duncan, Omer Ronen, and Aaron Kornblith