Caching is a common concept in computer technology that considerably enhances the efficiency of storage and retrieval systems by keeping a subset of popular products better to the customer based upon demand patterns. An essential algorithmic piece of cache management is the choice policy utilized for dynamically upgrading the set of products being saved, which has actually been thoroughly enhanced over numerous years, leading to numerous effective and robust heuristics While using maker finding out to cache policies has actually revealed appealing lead to current years (e.g., LRB, LHD, storage applications), it stays a difficulty to outshine robust heuristics in a manner that can generalize dependably beyond standards to production settings, while preserving competitive calculate and memory overheads.
In “ HALP: Heuristic Helped Learned Choice Expulsion Policy for YouTube Material Shipment Network“, provided at NSDI 2023, we present a scalable modern cache expulsion structure that is based upon discovered benefits and usages choice knowing with automated feedback. The Heuristic Helped Found Out Choice (HALP) structure is a meta-algorithm that utilizes randomization to combine a light-weight heuristic standard expulsion guideline with a discovered benefit design. The benefit design is a light-weight neural network that is continually trained with continuous automatic feedback on choice contrasts created to imitate the offline oracle We talk about how HALP has actually enhanced facilities effectiveness and user video playback latency for YouTube’s content shipment network
Discovered choices for cache expulsion choices
The HALP structure calculates cache expulsion choices based upon 2 parts: (1) a neural benefit design trained with automated feedback by means of choice knowing, and (2) a meta-algorithm that integrates a discovered benefit design with a quick heuristic. As the cache observes inbound demands, HALP continually trains a little neural network that forecasts a scalar benefit for each product by developing this as a choice knowing technique by means of pairwise choice feedback. This element of HALP resembles support knowing from human feedback (RLHF) systems, however with 2 essential differences:.
- Feedback is automated and leverages widely known outcomes about the structure of offline ideal cache expulsion policies.
- The design is discovered continually utilizing a short-term buffer of training examples built from the automated feedback procedure.
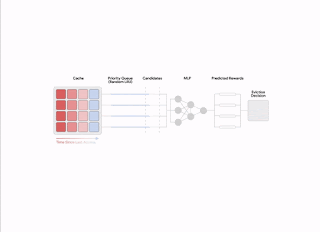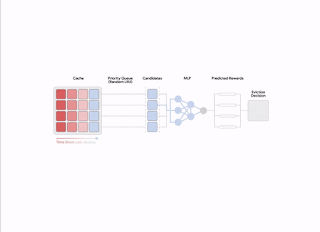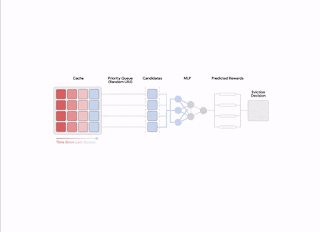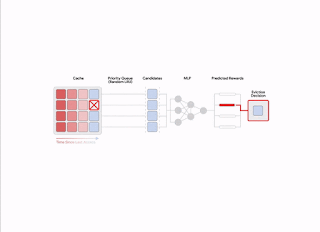
The expulsion choices depend on a filtering system with 2 actions. Initially, a little subset of prospects is picked utilizing a heuristic that is effective, however suboptimal in regards to efficiency. Then, a re-ranking action enhances from within the standard prospects by means of the sparing usage of a neural network scoring function to “increase” the quality of the decision.
As a production prepared cache policy execution, HALP not just makes expulsion choices, however likewise subsumes the end-to-end procedure of tasting pairwise choice questions utilized to effectively build pertinent feedback and upgrade the design to power expulsion choices.
A neural benefit design
HALP utilizes a light-weight two-layer multilayer perceptron (MLP) as its benefit design to selectively score private products in the cache. The functions are built and handled as a metadata-only “ghost cache” (comparable to classical policies like ARC). After any provided lookup demand, in addition to routine cache operations, HALP carries out the book-keeping (e.g., tracking and upgrading function metadata in a capacity-constrained key-value shop) required to upgrade the vibrant internal representation. This consists of: (1) externally tagged functions supplied by the user as input, together with a cache lookup demand, and (2) internally built vibrant functions (e.g., time because last gain access to, typical time in between gain access to) built from lookup times observed on each product.
HALP discovers its benefit design totally online beginning with a random weight initialization. This may look like a bad concept, particularly if the choices are made solely for enhancing the benefit design. Nevertheless, the expulsion choices depend on both the discovered benefit design and a suboptimal however easy and robust heuristic like LRU This enables ideal efficiency when the benefit design has actually totally generalized, while staying robust to a briefly uninformative benefit design that is yet to generalize, or in the procedure of reaching an altering environment.
Another benefit of online training is expertise. Each cache server runs in a possibly various environment (e.g., geographical area), which affects regional network conditions and what material is in your area popular, to name a few things. Online training immediately records this details while minimizing the problem of generalization, rather than a single offline training service.
Scoring samples from a randomized concern line
It can be not practical to enhance for the quality of expulsion choices with a solely discovered goal for 2 factors.
- Compute effectiveness restraints: Reasoning with a discovered network can be considerably more pricey than the calculations carried out in useful cache policies running at scale. This restricts not just the expressivity of the network and functions, however likewise how typically these are conjured up throughout each expulsion choice.
- Effectiveness for generalizing out-of-distribution: HALP is released in a setup that includes continuous knowing, where a rapidly altering work may produce demand patterns that may be briefly out-of-distribution with regard to formerly seen information.
To attend to these concerns, HALP initially uses an economical heuristic scoring guideline that represents an expulsion concern to recognize a little prospect sample. This procedure is based upon effective random tasting that estimates precise concern lines The concern function for creating prospect samples is planned to be fast to calculate utilizing existing manually-tuned algorithms, e.g., LRU. Nevertheless, this is configurable to approximate other cache replacement heuristics by modifying a basic expense function. Unlike previous work, where the randomization was utilized to tradeoff approximation for effectiveness, HALP likewise relies on the fundamental randomization in the tested prospects throughout time actions for offering the essential exploratory variety in the tested prospects for both training and reasoning.
The last kicked out product is selected from amongst the provided prospects, comparable to the best-of-n reranked sample, representing making the most of the anticipated choice rating according to the neural benefit design. The very same swimming pool of prospects utilized for expulsion choices is likewise utilized to build the pairwise choice questions for automated feedback, which assists reduce the training and reasoning alter in between samples.
 |
| An introduction of the two-stage procedure conjured up for each expulsion choice. |
Online choice finding out with automated feedback
The benefit design is discovered utilizing online feedback, which is based upon immediately appointed choice labels that suggest, any place possible, the ranked choice purchasing for the time required to get future re-accesses, beginning with an offered picture in time amongst each queried sample of products. This resembles the oracle ideal policy, which, at any provided time, forces out a product with the farthest future gain access to from all the products in the cache.
 |
| Generation of the automated feedback for finding out the benefit design. |
To make this feedback procedure helpful, HALP constructs pairwise choice questions that are more than likely to be pertinent for expulsion choices. In sync with the normal cache operations, HALP concerns a little number of pairwise choice questions while making each expulsion choice, and adds them to a set of pending contrasts. The labels for these pending contrasts can just be dealt with at a random future time. To run online, HALP likewise carries out some extra book-keeping after each lookup demand to process any pending contrasts that can be identified incrementally after the present demand. HALP indexes the pending contrast buffer with each aspect associated with the contrast, and recycles the memory taken in by stagnant contrasts (neither of which might ever get a re-access) to guarantee that the memory overhead connected with feedback generation stays bounded with time.
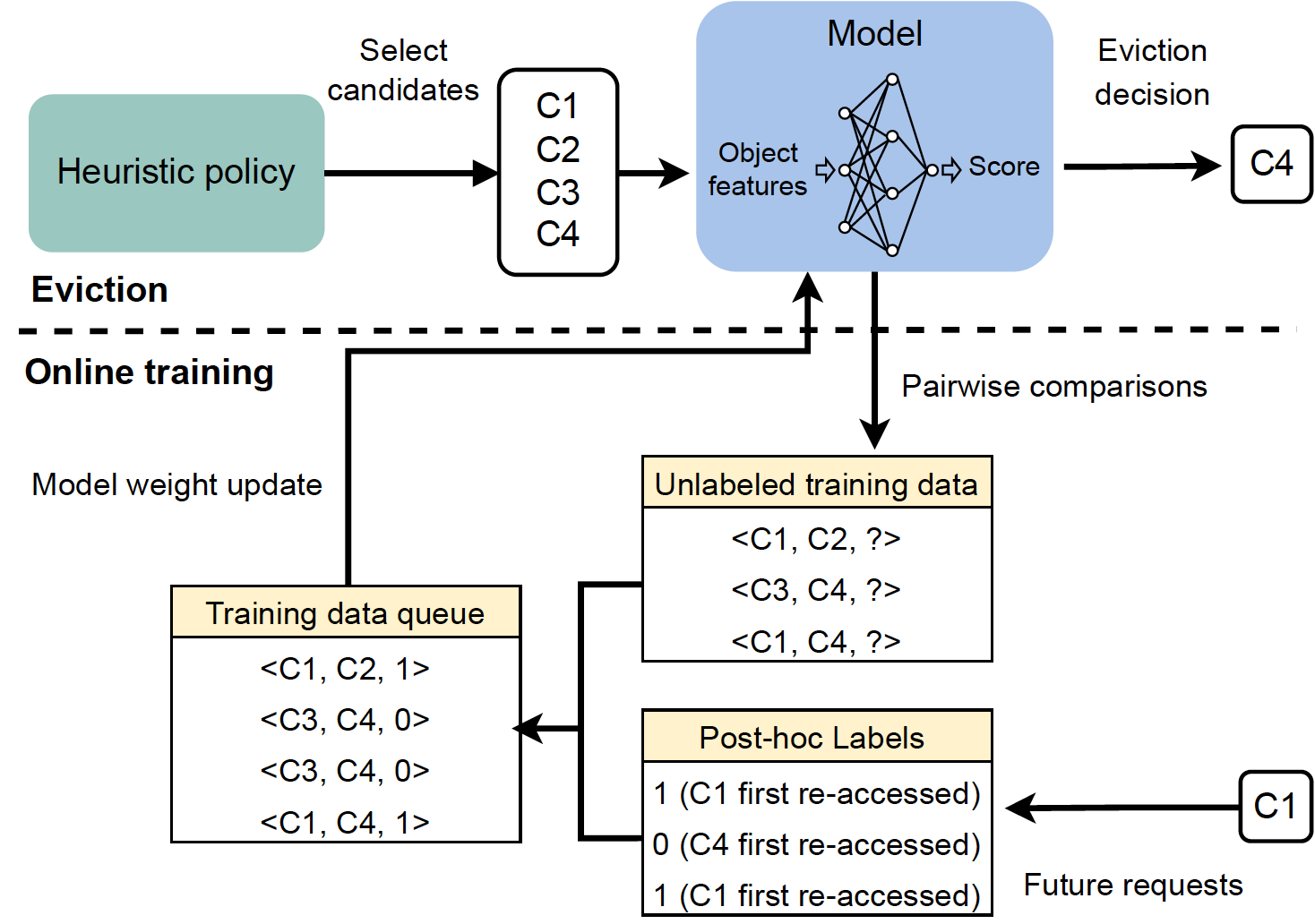 |
| Summary of all primary parts in HALP. |
Outcomes: Effect On the YouTube CDN
Through empirical analysis, we reveal that HALP compares positively to modern cache policies on public benchmark traces in regards to cache miss out on rates. Nevertheless, while public standards are a beneficial tool, they are seldom adequate to catch all the use patterns throughout the world over time, not to discuss the varied hardware setups that we have actually currently released.
Up until just recently, YouTube servers utilized an enhanced LRU-variant for memory cache expulsion. HALP increases YouTube’s memory egress/ingress– the ratio of the overall bandwidth egress served by the CDN to that taken in for retrieval (ingress) due to cache misses out on– by approximately 12% and memory hit rate by 6%. This minimizes latency for users, because memory checks out are much faster than disk checks out, and likewise enhances egressing capability for disk-bounded makers by protecting the disks from traffic.
The figure listed below programs an aesthetically engaging decrease in the byte miss out on ratio in the days following HALP’s last rollout on the YouTube CDN, which is now serving considerably more content from within the cache with lower latency to the end user, and without needing to turn to more pricey retrieval that increases the operating expense.
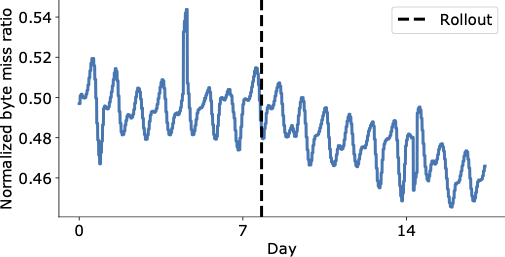 |
| Aggregate around the world YouTube byte miss out on ratio prior to and after rollout (vertical rushed line). |
An aggregated efficiency enhancement might still conceal essential regressions. In addition to determining total effect, we likewise carry out an analysis in the paper to comprehend its influence on various racks utilizing a device level analysis, and discover it to be extremely favorable.
Conclusion
We presented a scalable modern cache expulsion structure that is based upon discovered benefits and usages choice knowing with automated feedback. Since of its style options, HALP can be released in a way comparable to any other cache policy without the functional overhead of needing to individually handle the identified examples, training treatment and the design variations as extra offline pipelines typical to the majority of maker finding out systems. For that reason, it sustains just a little additional overhead compared to other classical algorithms, however has actually the included advantage of having the ability to make the most of extra functions to make its expulsion choices and continually adjust to altering gain access to patterns.
This is the very first massive release of a discovered cache policy to a commonly utilized and greatly trafficked CDN, and has actually considerably enhanced the CDN facilities effectiveness while likewise providing a much better quality of experience to users.
Recognitions
Ramki Gummadi is now part of Google DeepMind. We wish to thank John Guilyard for aid with the illustrations and Richard Schooler for feedback on this post.