What is Web Scraping and Why is it used?
Data is a universal need to solve business and research problems. Questionnaires, surveys, interviews, and forms are all data collection methods; however, they don’t quite tap into the biggest data resource available. The Internet is a huge reservoir of data on every plausible subject. Unfortunately, most websites do not allow the option to save and retain the data which can be seen on their web pages. Web scraping solves this problem and enables users to scrape large volumes of the needed data.
Web scraping is the automated gathering of content and data from a website or any other resource available on the internet. Unlike screen scraping, web scraping extracts the HTML code under the webpage. Users can then process the HTML code of the webpage to extract data and carry out data cleaning, manipulation, and analysis.
Exhaustive amounts of this data can even be stored in a database for large-scale data analysis projects. The prominence and need for data analysis, along with the amount of raw data which can be generated using web scrapers, has led to the development of tailor-made python packages which make web scraping easy as pie.
Applications of Web Scraping
- Sentiment analysis: While most websites used for sentiment analysis, such as social media websites, have APIs which allow users to access data, this is not always enough. In order to obtain data in real-time regarding information, conversations, research, and trends it is often more suitable to web scrape the data.
- Market Research: eCommerce sellers can track products and pricing across multiple platforms to conduct market research regarding consumer sentiment and competitor pricing. This allows for very efficient monitoring of competitors and price comparisons to maintain a clear view of the market.
- Technological Research: Driverless cars, face recognition, and recommendation engines all require data. Web Scraping often offers valuable information from reliable websites and is one of the most convenient and used data collection methods for these purposes.
- Machine Learning: While sentiment analysis is a popular machine learning algorithm, it is only one of many. One thing all machine learning algorithms have in common, however, is the large amount of data required to train them. Machine learning fuels research, technological advancement, and overall growth across all fields of learning and innovation. In turn, web scraping can fuel data collection for these algorithms with great accuracy and reliability.
Understanding the Role of Selenium and Python in Scraping
Python has libraries for almost any purpose a user can think up, including libraries for tasks such as web scraping. Selenium comprises several different open-source projects used to carry out browser automation. It supports bindings for several popular programming languages, including the language we will be using in this article: Python.
Initially, Selenium with Python was developed and used primarily for cross-browser testing; however, over time more creative use cases such as selenium and python web scrapping have been found.
Selenium uses the Webdriver protocol to automate processes on various popular browsers such as Firefox, Chrome, and Safari. This automation can be carried out locally (for purposes such as testing a web page) or remotely (for web scraping).
Example: Web Scraping the Title and all Instances of a Keyword from a Specified URL
The general process followed when performing web scraping is:
- Use the webdriver for the browser being used to get a specific URL.
- Perform automation to obtain the information required.
- Download the content required from the webpage returned.
- Perform data parsing and manipulation on the content.
- Reformat, if needed, and store the data for further analysis.
In this example, user input is taken for the URL of an article. Selenium is used along with BeautifulSoup to scrape and then carry out data manipulation to obtain the title of the article, and all instances of a user input keyword found in it. Following this, a count is taken of the number of cases found of the keyword, and all this text data is stored and saved in a text file called article_scraping.txt.
How to perform Web Scraping using Selenium and Python
Pre-Requisites:
- Set up a Python Environment.
- Install Selenium v4. If you have conda or anaconda set up then using the pip package installer would be the most efficient method for Selenium installation. Simply run this command (on anaconda prompt, or directly on the Linux terminal):
pip install selenium
- Download the latest WebDriver for the browser you wish to use, or install webdriver_manager by running the command, also install BeautifulSoup:
pip install webdriver_manager
pip install beautifulsoup4
Step 1: Import the required packages.
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom bs4 import BeautifulSoupimport codecsimport refrom webdriver_manager.chrome import ChromeDriverManager
Selenium is needed in order to carry out web scraping and automate the chrome browser we’ll be using. Selenium uses the webdriver protocol, therefore the webdriver manager is imported to obtain the ChromeDriver compatible with the version of the browser being used. BeautifulSoup is needed as an HTML parser, to parse the HTML content we scrape. Re is imported in order to use regex to match our keyword. Codecs are used to write to a text file.
Step 2: Obtain the version of ChromeDriver compatible with the browser being used.
driver=webdriver.Chrome(service=Service(ChromeDriverManager().install()))
Step 3: Take the user input to obtain the URL of the website to be scraped, and web scrape the page.
val = input("Enter a url: ")wait = WebDriverWait(driver, 10)driver.get(val)
get_url = driver.current_url
wait.until(EC.url_to_be(val))
if get_url == val:
page_source = driver.page_source
The driver is used to get this URL and a wait command is used in order to let the page load. Then a check is done using the current URL method to ensure that the correct URL is being accessed.
Step 4: Use BeautifulSoup to parse the HTML content obtained.
soup = BeautifulSoup(page_source,features="html.parser")
keyword=input("Enter a keyword to find instances of in the article:")
matches = soup.body.find_all(string=re.compile(keyword))len_match = len(matches)title = soup.title.text
The HTML content web scraped with Selenium is parsed and made into a soup object. Following this, user input is taken for a keyword for which we will search the article’s body. The keyword for this example is “data“. The body tags in the soup object are searched for all instances of the word “data” using regex. Lastly, the text in the title tag found within the soup object is extracted.
Step 4: Store the data collected into a text file.
file=codecs.open('article_scraping.txt', 'a+')file.write(title+"n")file.write("The following are all instances of your keyword:n")count=1for i in matches:file.write(str(count) + "." + i + "n")count+=1file.write("There were "+str(len_match)+" matches found for the keyword."file.close()driver.quit()
Use codecs to open a text file titled article_scraping.txt and write the title of the article into the file, following this number, and append all instances of the keyword within the article. Lastly, append the number of matches found for the keyword in the article. Close the file and quit the driver.
Output:
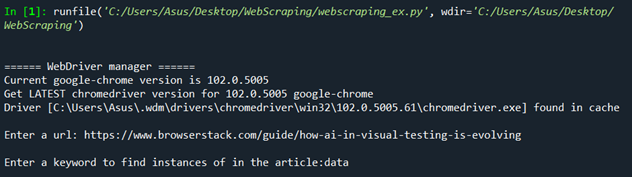
Text File Output:
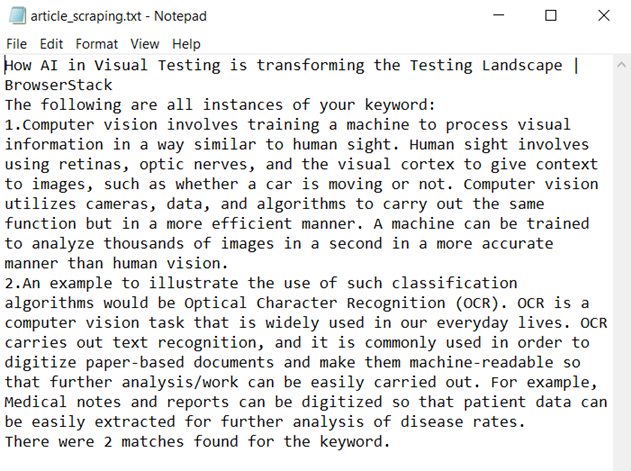
The title of the article, the two instances of the keyword, and the number of matches found can be visualized in this text file.
How to use tags to efficiently collect data from web-scraped HTML pages:
print([tag.name for tag in soup.find_all()])print([tag.text for tag in soup.find_all()])
The above code snippet can be used to print all the tags found in the soup object and all text within those tags. This can be helpful to debug code or locate any errors and issues.
Other Features of Selenium with Python
You can use some of Selenium’s inbuilt features to carry out further actions or perhaps automate this process for multiple web pages. The following are some of the most convenient features offered by Selenium to carry out efficient Browser Automation and Web Scraping with Python:
- Filling out forms or carrying out searches
Example of Google search automation using Selenium with Python.
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom webdriver_manager.chrome import ChromeDriverManagerfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.google.com/")search = driver.find_element(by=By.NAME,value="q")search.send_keys("Selenium")search.send_keys(Keys.ENTER)
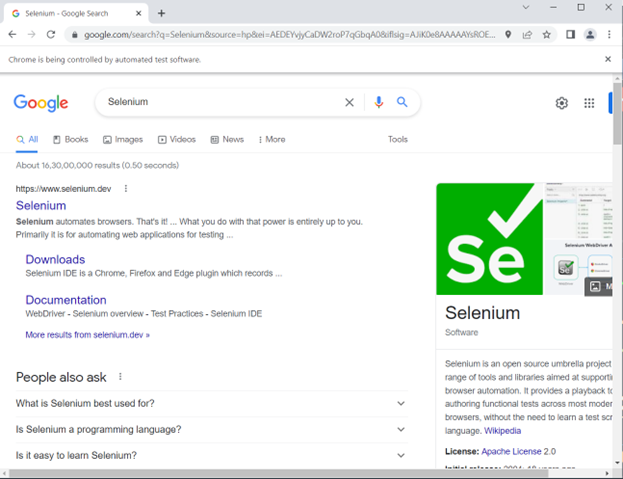
First, the driver loads google.com, which finds the search bar using the name locator. It types “Selenium” into the searchbar and then hits enter.
Output:
- Maximizing the window
driver.maximize_window()
- Taking Screenshots
driver.save_screenshot('article.png')
- Using locators to find elements
Let’s say we don’t want to get the entire page source and instead only want to web scrape a select few elements. This can be carried out by using Locators in Selenium.
These are some of the locators compatible for use with Selenium:
- Name
- ID
- Class Name
- Tag Name
- CSS Selector
- XPath
Example of scraping using locators:
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byfrom webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
val = input("Enter a url: ")
wait = WebDriverWait(driver, 10)driver.get(val)get_url = driver.current_urlwait.until(EC.url_to_be(val))if get_url == val:header=driver.find_element(By.ID, "toc0")print(header.text)
This example’s input is the same article as the one in our web scraping example. Once the webpage has loaded the element we want is directly retrieved via ID, which can be found by using Inspect Element.
Output:

The title of the first section is retrieved by using its locator “toc0” and printed.
- Scrolling
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
This scrolls to the bottom of the page and is often helpful for websites that have infinite scrolling.
Conclusion
This guide explained the process of Web Scraping, Parsing, and Storing the Data collected. It also explored Web Scraping specific elements using locators in Python with Selenium. Furthermore, it provided guidance on how to automate a web page so that the desired data can be retrieved. The information provided should prove to be of service to carry out reliable data collection and perform insightful data manipulation for further downstream data analysis.
It is recommended to run Selenium Tests on a real device cloud for more accurate results since it considers real user conditions while running tests. With BrowserStack Automate, you can access 3000+ real device-browser combinations and test your web application thoroughly for a seamless and consistent user experience.
The post How to perform Web Scraping using Selenium and Python appeared first on Datafloq.