Big Language Designs (LLMs) like PaLM or GPT-3 revealed that scaling transformers to numerous billions of specifications enhances efficiency and opens emerging capabilities The greatest thick designs for image understanding, nevertheless, have actually reached just 4 billion specifications, in spite of research study suggesting that appealing multimodal designs like PaLI continue to take advantage of scaling vision designs together with their language equivalents. Encouraged by this, and the arise from scaling LLMs, we chose to carry out the next action in the journey of scaling the Vision Transformer
In “ Scaling Vision Transformers to 22 Billion Criteria“, we present the greatest thick vision design, ViT-22B. It is 5.5 x bigger than the previous biggest vision foundation, ViT-e, which has 4 billion specifications. To allow this scaling, ViT-22B includes concepts from scaling text designs like PaLM, with enhancements to both training stability (utilizing QK normalization) and training performance (with an unique method called asynchronous parallel direct operations). As an outcome of its customized architecture, effective sharding dish, and bespoke execution, it had the ability to be trained on Cloud TPUs with a high hardware usage 1 ViT-22B advances the cutting-edge on lots of vision jobs utilizing frozen representations, or with complete fine-tuning. Even more, the design has actually likewise been effectively utilized in PaLM-e, which revealed that a big design integrating ViT-22B with a language design can substantially advance the cutting-edge in robotics jobs.
Architecture
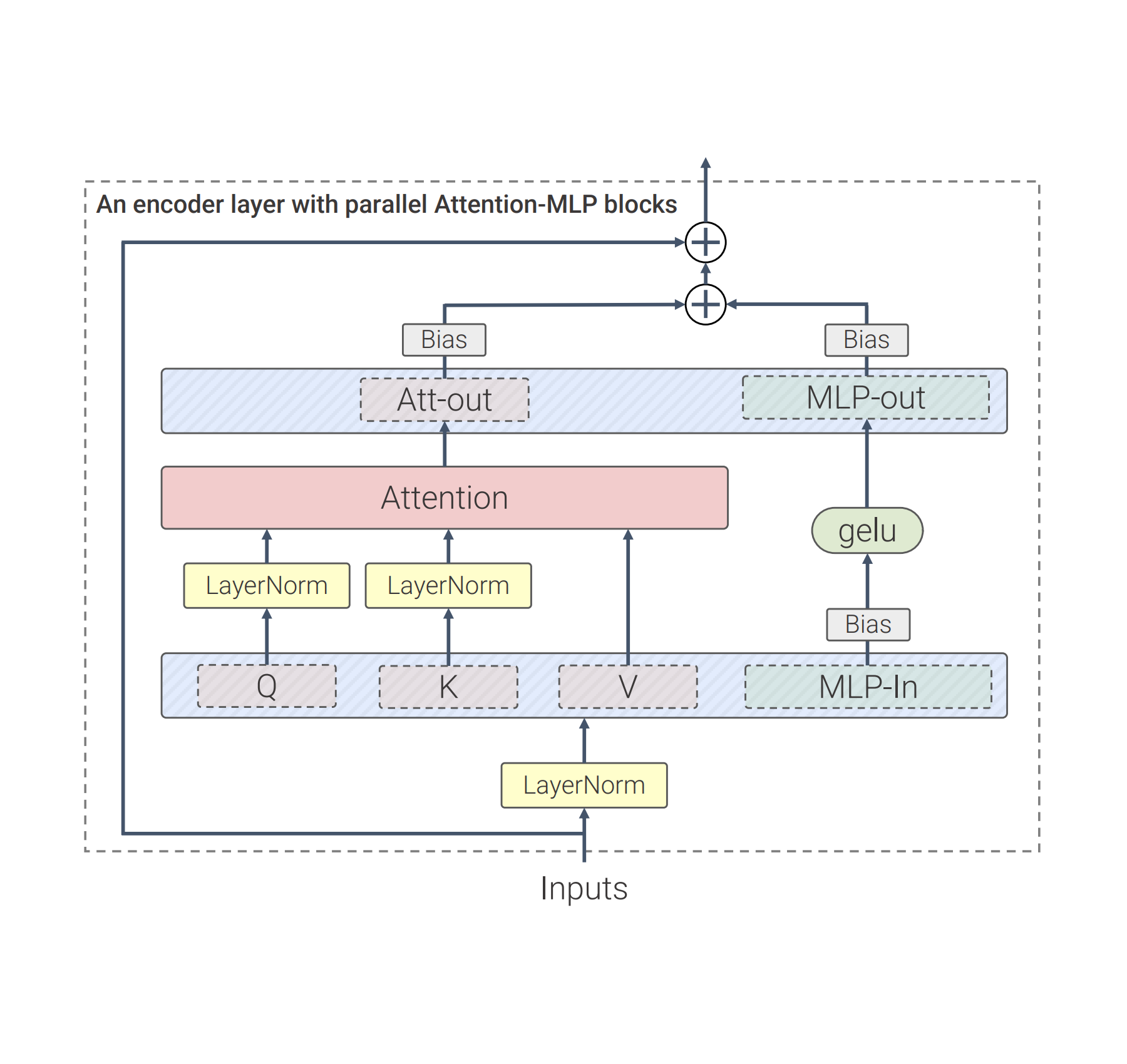
Our work constructs on lots of advances from LLMs, such as PaLM and GPT-3. Compared to the basic Vision Transformer architecture, we utilize parallel layers, a technique in which attention and MLP obstructs are performed in parallel, rather of sequentially as in the basic Transformer. This method was utilized in PaLM and lowered training time by 15%.
Second of all, ViT-22B leaves out predispositions in the QKV forecasts, part of the self-attention system, and in the LayerNorms, which increases usage by 3%. The diagram listed below programs the customized transformer architecture utilized in ViT-22B:.
 |
| ViT-22B transformer encoder architecture utilizes parallel feed-forward layers, leaves out predispositions in QKV and LayerNorm layers and stabilizes Question and Secret forecasts. |
Designs at this scale demand “sharding”– dispersing the design specifications in various calculate gadgets. Along with this, we likewise shard the activations (the intermediate representations of an input). Even something as basic as a matrix reproduction requires additional care, as both the input and the matrix itself are dispersed throughout gadgets. We establish a technique called asynchronous parallel direct operations, where interactions of activations and weights in between gadgets happen at the very same time as calculations in the matrix increase system (the part of the TPU holding the large bulk of the computational capability). This asynchronous method lessens the time waiting on inbound interaction, hence increasing gadget performance. The animation listed below programs an example calculation and interaction pattern for a matrix reproduction.
 |
| Asynchronized parallel direct operation. The objective is to calculate the matrix reproduction y = Ax, however both the matrix A and activation x are dispersed throughout various gadgets. Here we highlight how it can be made with overlapping interaction and calculation throughout gadgets. The matrix A is column-sharded throughout the gadgets, each holding an adjoining piece, each block represented as A ij More information remain in the paper. |
Initially, the brand-new design scale led to serious training instabilities. The normalization method of Gilmer et al. (2023, upcoming) solved these concerns, making it possible for smooth and steady design training; this is detailed listed below with example training developments.
 |
| The result of stabilizing the questions and secrets (QK normalization) in the self-attention layer on the training characteristics. Without QK normalization (red) gradients end up being unsteady and the training loss diverges. |
Outcomes
Here we highlight some outcomes of ViT-22B. Keep in mind that in the paper we likewise check out numerous other issue domains, like video category, depth evaluation, and semantic division
To highlight the richness of the discovered representation, we train a text design to produce representations that line up text and image representations (utilizing LiT-tuning). Listed below we reveal numerous outcomes for out-of-distribution images created by Parti and Imagen:.
 |
| Examples of image+ text understanding for ViT-22B coupled with a text design. The chart reveals stabilized likelihood circulation for each description of an image. |
Human things acknowledgment positioning
To discover how lined up ViT-22B category choices are with human category choices, we examined ViT-22B fine-tuned with various resolutions on out-of-distribution (OOD) datasets for which human contrast information is readily available by means of the model-vs-human tool kit This tool kit determines 3 essential metrics: How well do designs manage distortions (precision)? How various are human and model precisions (precision distinction)? Lastly, how comparable are human and model mistake patterns (mistake consistency)? While not all fine-tuning resolutions carry out similarly well, ViT-22B variations are cutting-edge for all 3 metrics. In addition, the ViT-22B designs likewise have the greatest ever tape-recorded shape predisposition in vision designs. This indicates that they primarily utilize things shape, instead of things texture, to notify category choices– a technique understood from human understanding (which has a shape predisposition of 96%). Requirement designs (e.g., ResNet-50, which has aa ~ 20– 30% shape predisposition) frequently categorize images like the feline with elephant texture listed below according to the texture (elephant); designs with a high shape predisposition tend to concentrate on the shape rather (feline). While there are still lots of essential distinctions in between human and model understanding, ViT-22B programs increased resemblances to human visual things acknowledgment.
 |
| Feline or elephant? Cars and truck or clock? Bird or bike? Example images with the shape of one things and the texture of a various things, utilized to determine shape/texture predisposition. |
 |
| Forming predisposition assessment (greater = more shape-biased). Lots of vision designs have a low shape/ high texture predisposition, whereas ViT-22B fine-tuned on ImageNet (red, green, blue trained on 4B images as suggested by brackets after design names, unless trained on ImageNet just) have the greatest shape predisposition tape-recorded in a ML design to date, bringing them closer to a human-like shape predisposition. |
Out-of-distribution efficiency
Determining efficiency on OOD datasets assists examine generalization. In this experiment we build label-maps (mappings of labels in between datasets) from JFT to ImageNet and likewise from ImageNet to various out-of-distribution datasets like ObjectNet (outcomes after pre-training on this information displayed in the left curve listed below). Then the designs are totally fine-tuned on ImageNet.
We observe that scaling Vision Transformers increases OOD efficiency: although ImageNet precision fills, we see a considerable boost on ObjectNet from ViT-e to ViT-22B (revealed by the 3 orange dots in the upper right listed below).
 |
| Despite the fact that ImageNet precision fills, we see a considerable boost in efficiency on ObjectNet from ViT-e/14 to ViT-22B. |
Direct probe
Direct probe is a method where a single direct layer is trained on top of a frozen design. Compared to complete fine-tuning, this is more affordable to train and much easier to establish. We observed that the direct probe of ViT-22B efficiency approaches that of advanced complete fine-tuning of smaller sized designs utilizing high-resolution images (training with greater resolution is normally a lot more costly, however for lots of jobs it yields much better outcomes). Here are outcomes of a direct probe trained on the ImageNet dataset and examined on the ImageNet recognition dataset and other OOD ImageNet datasets.
Distillation
The understanding of the larger design can be moved to a smaller sized design utilizing the distillation technique This is handy as huge designs are slower and more costly to utilize. We discovered that ViT-22B understanding can be moved to smaller sized designs like ViT-B/16 and ViT-L/16, attaining a brand-new cutting-edge on ImageNet for those design sizes.
Fairness and predisposition
ML designs can be prone to unexpected unjust predispositions, such as getting spurious connections (determined utilizing market parity) or having efficiency spaces throughout subgroups. We reveal that scaling up the size assists in reducing such concerns.
Initially, scale uses a more beneficial tradeoff frontier– efficiency enhances with scale even when the design is post-processed after training to manage its level of market parity listed below a recommended, bearable level. Significantly, this holds not just when efficiency is determined in regards to precision, however likewise other metrics, such as calibration, which is an analytical procedure of the truthfulness of the design’s approximated possibilities. Second, category of all subgroups tends to enhance with scale as shown listed below. Third, ViT-22B lowers the efficiency space throughout subgroups.
 |
 |
| Leading: Precision for each subgroup in CelebA prior to debiasing. Bottom: The y-axis reveals the outright distinction in efficiency throughout the 2 particular subgroups highlighted in this example: women and males. ViT-22B has a little space in efficiency compared to smaller sized ViT architectures. |
Conclusions
We have actually provided ViT-22B, presently the biggest vision transformer design at 22 billion specifications. With little however important modifications to the initial architecture, we attained outstanding hardware usage and training stability, yielding a design that advances the cutting-edge on numerous criteria. Piece de resistance can be attained utilizing the frozen design to produce embeddings and after that training thin layers on top. Our assessments even more reveal that ViT-22B programs increased resemblances to human visual understanding when it pertains to form and texture predisposition, and uses advantages in fairness and effectiveness, when compared to existing designs.
Recognitions
This is a joint work of Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd van Steenkiste, Gamaleldin Fathy, Elsayed Aravindh Mahendran, Fisher Yu, Avital Oliver, Fantine Huot, Jasmijn Bastings, Mark Patrick Collier, Alexey Gritsenko, Vighnesh Birodkar, Cristina Vasconcelos, Yi Tay, Thomas Mensink, Alexander Kolesnikov, Filip PavetiÄ, Dustin Tran, Thomas Kipf, Mario LuÄiÄ, Xiaohua Zhai, Daniel Keysers Jeremiah Harmsen, and Neil Houlsby
We wish to thank Jasper Uijlings, Jeremy Cohen, Arushi Goel, Radu Soricut, Xingyi Zhou, Lluis Castrejon, Adam Paszke, Joelle Barral, Federico Lebron, Blake Hechtman, and Peter Hawkins. Their competence and steady assistance played a vital function in the conclusion of this paper. We likewise acknowledge the partnership and commitment of the skilled scientists and engineers at Google Research study.
1 Note: ViT-22B has 54.9% design FLOPs usage (MFU) while PaLM reported.
46.2% MFU and we determined 44.0% MFU for ViT-e on the very same hardware. â©