
Device finding out and AI builders are desperate to get their palms on PyTorch 2.0, which used to be unveiled in past due 2022 and is because of transform to be had this month. Some of the options greeting keen ML builders is a compiler in addition to new optimizations for CPUs.
PyTorch is a well-liked device finding out library advanced via Fbâs AI Analysis lab (FAIR) and launched to open supply in 2016. The Python-based library, which used to be advanced atop the Torch clinical computing framework, is used to construct and educate neural networks, comparable to the ones used for enormous language fashions (LLMs), comparable to GPT-4, and pc imaginative and prescient programs.
The primary experimental unencumber of PyTorch 2.0 used to be unveiled in December via the PyTorch Basis, which used to be arrange underneath the Linux Basis simply 3 months previous. Now the PyTorch Basis is gearing as much as release the primary solid unencumber of PyTorch 2.0 this month.
Some of the largest improvements in PyTorch 2.0 is torch.collect. In line with the PyTorch Basis, the brand new compiler is designed to be a lot quicker than the former on-the-fly era of code presented within the default âkeen modeâ in PyTorch 1.0.
The brand new compiler wraps plenty of applied sciences into the library, together with TorchDynamo, AOTAutograd, PrimTorch and TorchInductor. All of those have been advanced in Python, versus C++ (which Python is appropriate with). The release of two.0 âbegins the transferâ again to Python from C++, the PyTorch Basis says, including âit is a considerable new route for PyTorch.â
âFrom day one, we knew the efficiency limits of keen execution,â the PyTorch Basis writes. âIn July 2017, we began our first analysis venture into growing a Compiler for PyTorch. The compiler had to make a PyTorch program rapid, however now not at the price of the PyTorch revel in. Our key standards used to be to keep sure sorts of flexibilityâfortify for dynamic shapes and dynamic techniques which researchers use in quite a lot of phases of exploration.â
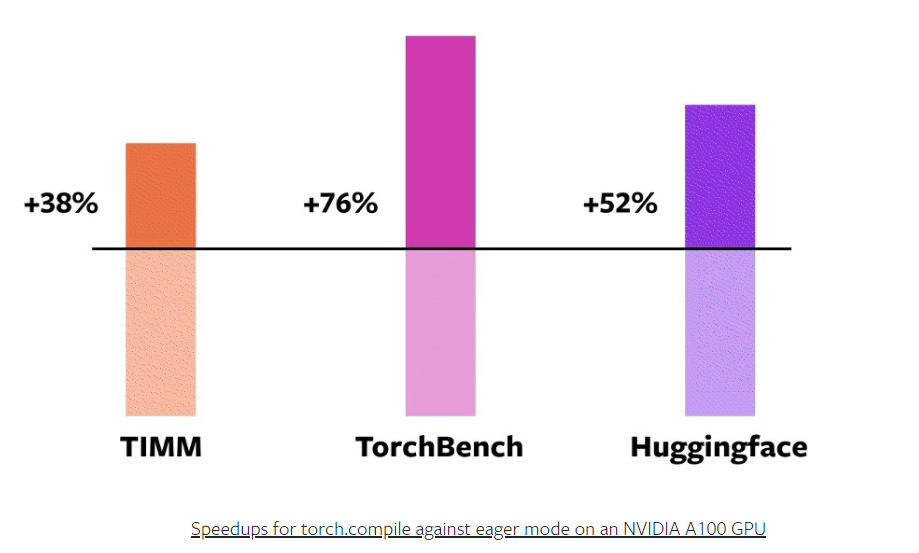
PyTorch 2.0 compilation speedup on decided on fashions (Supply: PyTorch Basis)
The PyTorch Basis expects customers to start out within the non-compiled âkeen mode,â which makes use of dynamic on-the-fly code generator, and continues to be to be had in 2.0. Nevertheless it expects the builders to temporarily transfer as much as the compiled mode the use of the porch.collect command, which can also be executed with the addition of a unmarried line of code, it says.
Customers can be expecting to peer a 43% spice up in compilation time with 2.0 over 1.0, in step with the PyTorch Basis. This quantity comes from benchmark checks that PyTorch Basis ran the use of PyTorch 2.0 on an Nvidia A100 GPU in opposition to 163 open supply fashions, together with HuggingFace Tranformers, TIMM, and TorchBench.
In line with PyTorch Basis, the brand new compiler ran 21% quicker when the use of Float32 precision mode and ran 51% quicker when the use of Automated Combined Precision (AMP) mode. The brand new torch.collect mode labored 93% of the time, the basis mentioned.
âWithin the roadmap of PyTorch 2.x we are hoping to push the compiled mode additional and extra with regards to efficiency and scalability. A few of this paintings is in-flight,â the PyTorch Basis mentioned. âA few of this paintings has now not began but. A few of this paintings is what we are hoping to peer, however donât have the bandwidth to do ourselves.â
One of the vital firms serving to to expand PyTorch 2.0 is Intel. The chipmaker contributed to quite a lot of portions of the brand new compiler stack, together with TorchInductor, GNN, INT8 inference optimization, and the oneDNN Graph API.
Intelâs Susan Kahler, who works on AI/ML merchandise and answers, described the contributions to the brand new compiler in a weblog.
âThe TorchInductor CPU backend is speeded up via leveraging the applied sciences from the Intel Extension for PyTorch for Conv/GEMM ops with post-op fusion and weight prepacking, and PyTorch ATen CPU kernels for memory-bound ops with specific vectorization on most sensible of OpenMP-based thread parallelization,â she wrote.
PyTorch and Googleâs TensorFlow are the 2 hottest deep finding out frameworks. Hundreds of organizations around the globe are growing deep finding out programs the use of PyTorch, and itâs use is rising.
The release of PyTorch 2.0 will lend a hand to boost up building of deep finding out and AI programs, says Luca Antiga the CTO of Lightning AI and one of the crucial number one maintainers of PyTorch Lightning
âPyTorch 2.0 embodies the way forward for deep finding out frameworks,â Antiga says. âThe chance to seize a PyTorch program with successfully no consumer intervention and get large on-device speedups and program manipulation out of the field unlocks an entire new measurement for AI builders.â
Similar Pieces:
GPT-4 Has Arrived: Right hereâs What to Know
OpenXLA Delivers Flexibility for ML Apps
PyTorch Upgrades to Cloud TPUs, Hyperlinks to R